Virtual Thread
기존 Java 스레드에 새롭게 추가되는 경량 스레드
JDK에 정식 도입되어 기존의 KLT(kernel-level thread)와 ULT(user-level thread)를 1:1 매핑하여 사용하는 JVM의 스레드 모델을 개선한, 여러 개의 가상 스레드를 하나의 네이티브 스레드에 할당하여 사용하는 모델
도입 배경
전통적인 Java 스레드 모델
기존 자바의 전통적인 스레드는 OS 스레드를 Wrapping한 Platform 스레드를 사용함

기존 Java의 Thread 모델은 Native Thread로,
java.util.concurrent.ExecutorService를 두어 JVM 내부에서java.lang.Thread객체를 관리/실행함Java 단의
ExecutorService를 통해 스케줄링되는 여러java.lang.Thread객체는 JVM에 존재하는start0함수를 JNI를 통해 호출하고, JVM은 커널 스레드를 만들어 실행함이러한 네이티브 호출은 JVM 내에서 스택과 분리되어 있는 네이티브 메서드 스택을 사용함
스케줄링은 Java(JVM의 스케줄링에 따라)에서, 실제 실행은 JNI를 통해 커널에서 실행됨
기존 Java 스레드 모델의 문제점
자바의 스레드는 OS의 스레드를 기반으로 함
자바의 스레드는 OS 스레드를 wrapping 한 것으로 platform 스레드라고 함
Java 애플리케이션에서 스레드를 사용하는 코드는 실제로 OS 스레드를 이용하는 방식으로 동작함
하지만 OS 커널에서 사용할 수 있는 스레드는 갯수가 제한적이고 생성 및 유지 비용이 바싸다는 단점이 존재
이를 해결하기 위해 비싼 자원인 스레드를 효율적으로 사용하기 위해서 스레드 풀을 사용해왔음
처리량(throughout)의 한계
기본적은 웹 요청 방식은 하나의 요청을 처리하기 위해서 하나의 스레드가 할당받아 처리하는 구조(Thread per Request 모델)
애플리케이션에서 처리량을 높이려면 스레드를 늘려야하지만, 이 스레드를 무한정 늘릴 수 없음(OS 스레드의 제약)
따라서 애플리케이션의 처리량은 스레드 풀에서 감당할 수 있는 범위를 넘어서 늘어날 수 없음
Blocking I/O로 인한 리소스 낭비
Thread per Request 모델에서는 요청을 처리하는 스레드에서 I/O 작업을 처리할 때 Blocking이 일어남
이 때문에 스레드는 I/O 작업이 끝날 때까지 다른 요청을 처리하지 못하고 기다려야 함
작업을 처리하는 시간보다 대기하는 시간이 길어짐
이 때문에 Blocking이 아닌 Non-blocking 방식의 Reactive Programming이 발전하였음
Blocking 방식을 Non-blocking 방식으로 변경하면서 다른 요청을 처리하는데 사용할 수 있게 됨
한정된 자원인 플랫폼 스레드가 Blocking 되면, 대기하는데 스레드 자원이 소요됨
대표적으로 Webflux가 이렇게 Non-blocking으로 동작하지만, 코드를 작성하고 이해하기 어렵다는 단점이 존재함
또한, 기존 자바 프로그래밍의 패러다임은 스레드를 기반으로 하기 때문에 라이브러리들 모두 Reactive 방식에 맞게 새롭게 작성되어야 한다는 문제가 있음
자바 플랫폼의 디자인
자바의 디자인은 기본적으로
스레드를 중심으로 설계되어 있어서 모든 작업이 스레드를 기반으로 일어남하지만 Reactive 스타일로 코드를 작성하면 사용자의 요청이 여러 스레드를 거쳐 작업이 진행되기 때문에 하나의 작업에 대한 예외나 디버깅 확인이 어려움
또한 Reactive하게 동작하는 별도의 라이브러리(R2DBC와 같은)가 필요하다는 단점이 존재
스레드는 프로세스의 공통 영역을 제외하고 만들어지기 때문에, 프로세스에 비해 크기가 작아 생성 비용이 작고, 컨텍스트 스위칭 비용이 저렴하다는 장점을 가지고 있다. 하지만 요청량이 급격하게 증가하는 서버 환경에서는 더 많은 스레드 수를 요구하게 되었고, 메모리가 제한된 환경에서 생성할 수 있는 스레드의 수는 한계가 있으며, 컨텍스트 스위칭 비용도 기하급수록적으로 늘어나게 되었다. 서버는 더 많은 요청 처리량과 컨텍스트 스위칭 비용을 줄여야했고, 이를 위해 나타난 스레드 모델이
경량 스레드모델인Virtual Thread이다.
Virtual Thread란?
JDK21(LTS)에 추가된 경량 스레드로, OS 스레드를 그대로 사용하지 않고 JVM 내부 스케줄링을 통해서 수백만개의 스레드를 동시에 사용할 수 있게 설계됨
가상 스레드가 해결하고자 하는 문제
Java 개발자가 하드웨어의 성능을 잘 활용하는 높은 처리량의 서버를 작성하는 것
가상 스레드는 Blocking이 발생하면 내부적으로 스케줄링을 활용하여 플랫폼 스레드가 그냥 대기하게 두지 않고, 다른 가상 스레드가 작업할 수 있도록 함
따라서 Reactive Programming의 Non-blocking과 동일하게 플랫폼 스레드의 리소스를 낭비하지 않음
동시에 자바 플랫폼의 디자인과 조화를 이루는 코드를 생성할 수 있도록 하는 것
기존 Reactive programming은 자바의 스레드 기반 설계로 Webflux 등을 사용할 때 디버깅, 성능테스트가 어려웠음
하지만 가상 스레드는 기존 스레드 구조를 그대로 사용하기 때문에 디버깅, 프로파일링 등 기존의 도구도 그대로 사용할 수 있음
Virtual Thread 구조

기존 Java의 스레드 모델과 달리, 플랫폼 스레드와 가상 스레드로 나뉨
플랫폼 스레드(ULT) 위에서 여러 Virtual Thread가 번갈아 가며 실행되는 형태로 동작함
기존
KLT(1) : ULT(1)의 구조가 아닌,KLT(1) : ULT(1) : Virtual Thread(N)의 구조로 사용
가상 스레드는 짧은 작업을 수행하는 동안 플랫폼 스레드에 의해 실행되고, 블로킹 작업이 발생하면 플랫폼 스레드에서 분리됨
플랫폼 스레드는 OS가 스케줄링 하지만, 가상 스레드는 JVM이 스케줄링 함
JVM은 가상 스레드를 플랫폼 스레드에 할당(mount)한 뒤, OS에게 스케줄링을 위임하여 일반적으로 플랫폼 스레드를 스케줄링할 수 있게 함
즉, 가상 스레드를 OS 스레드와 연결하기까지의 스케줄링은 JVM의 몫임
가상 스레드가 블로킹 작업(I/O 작업)이나 긴 대기 상태에 들어가면, JVM은 해당 가상 스레드를 플랫폼 스레드에서 분리(unmount)하여 다른 가상 스레드가 플랫폼 스레드를 사용할 수 있게 함
자원을 효율적으로 사용하고 많은 수의 가상 스레드를 처리할 수 있게 함
mount: 가상 스레드가 실제 실행을 위해 플랫폼 스레드에 할당(연결)되는 과정
unmount: 가상 스레드가 플랫폼 스레드에서 분리되는 과정
실제 구조

carrierThread기존에 OS와 1:1로 대응되어, 실제로 작업을 수행시키는 platform thread를 의미함
schedulerPlatform Thread의 기본 스케줄러는 ForkJoinPool을 사용함
스케줄러는 carrier thread의 pool을 관리하고, Virtual Thread의 작업 분배(스케줄링)를 담당함
runContinuationVirtual Thread의 실제 작업 내용(Runnable)
Virtual Thread의 동작 원리
carrierThread는 ForkJoinPool 안에Worker Thread로 생성이 되어 스케쥴링이 됨각
Worker Thread들은workQueue를 가지고 있어서 Task를 스케쥴링하는데,runContinuationrk가 Task가 되어서workQueue에 들어가게 됨workQueue에 있는runContinuation들은forkJoinPool의work stealing방식으로 carrier thread에 의해 처리됨처리되던 runContinuation들은 I/O, Sleep으로 인한 interrupt나 작업 완료 시, workQueue에서 pop되어 park과정에 의해 다시 힙 메모리로 되돌아감
Park: 스레드가 특정 조건이 충족될 때까지 실행을 중단하고 대기 상태로 전환하는 것
Unpark: 대기 중인 스레드가 다시 실행 가능하게 되는 것
Virtual Thread vs Reactive Programming
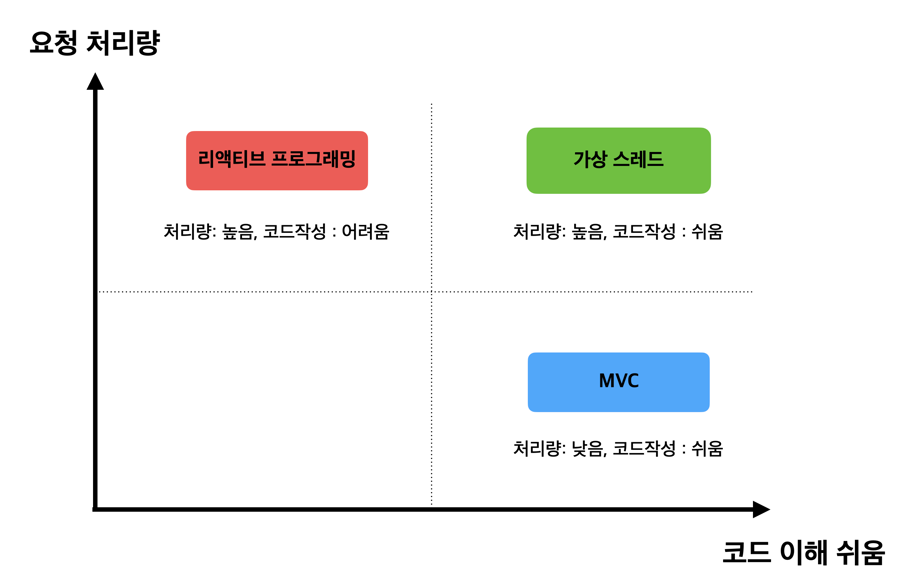
리소스를 효율적으로 사용하여 높은 처리량(throughput)을 감당하려는 목적은 동일함
가상 스레드를 사용하면 Non-blocking에 대한 처리를 JVM 레벨에서 담당함
따라서 Spring Web MVC 스타일로 코드를 작성하더라도 내부에서 가상 스레드가 기존의 플랫폼 스레드를 직접 사용하는 방식보다 효율적으로 스케줄링하여 처리량을 높일 수 있음
결론적으로 가상 스레드는 기존 스레드 방식의 이점을 누리면서도 Reactive programming의 장점을 취할 수 있음
정리
그래서 가상 스레드를 언제 사용해야 할까?
높은 동시성 처리
기존의 OS 스레드를 사용하는 방식에서는 스레드 수의 제한과 스케줄링 오버헤드로 인해 성능이 제한될 수 있음
하지만 가상 스레드는 이 문제를 해결하여 높은 동시성을 효율적으로 처리할 수 있음
블로킹 I/O 작업
가상 스레드는 블로킹 I/O 작업이 발생했을 때 플랫폼 스레드에서 분리되므로, 블로킹 작업이 플랫폼 스레드를 차지하지 않고 다른 작업을 처리할 수 있게 함
기존 코드와의 호환성
기존의 Java 스레드 모델을 그대로 사용하면서도 높은 처리량을 필요로 하는 경우, 가상 스레드는 코드를 크게 변경하지 않고도 성능 향상을 이룰 수 있음
비동기 프로그래밍 모델로의 전환 없이도 성능을 개선할 수 있음을 의미함
디버깅 및 프로파일링
기존의 디버깅 및 프로파일링 도구를 그대로 사용할 수 있음
따라서 새로운 패러다임에 대한 학습 없이도 기존 개발자들이 쉽게 적응할 수 있음
Ref
Last updated