Table Scan과 Index Scan
테이블에 저장된 데이터를 읽는 방식은 Full Table Scan과 Index Scan 두 가지로 크게 나뉜다.
테이블 전체 스캔(Table Full Scan)

개념
테이블에 속한 블록 전체(모든 데이터)를 읽어서 데이터를 찾는 방법
데이터베이스는 해당 테이블의 모든 레코드를 순차적으로 조회함
사용 케이스
WHERE 절의 조건문을 기준으로 활용할 인덱스가 없는 경우
전체 데이터 대비 대량의 데이터가 필요할 경우
집계 함수 사용시(COUNT, SUM)
특징
인덱스 유무와 관계없이 항상 사용 가능함
한 번의 I/O 요청으로 여러 블록을 한꺼번에 읽음
테이블 대부분의 데이터를 찾을 때 유리함
어떤 검색 조건을 사용하더라도 검색이 가능함
대규모 테이블에서 비효율적
조건에 맞는 데이터를 찾기 위해 모든 행을 검사해야 하므로 시간이 오래 걸림
인덱스 스캔(Index Scan)
개념
인덱스를 이용하여 데이터를 일정 부분 읽어서 ROWID로 테이블 레코드를 찾아가는 방법
ROWID: 테이블 레코드가 디스크 상에서 어디에 저장되었는지 가리키는 위치 정보
인덱스를 구성하는 컬럼 값을 기반으로 데이터를 추출하는 기법
사용 케이스
인덱스는 데이터베이스 테이블에서 특정 열에 대한 정보를 가지고 있기 때문에 해당 열을 사용하여 검색할 경우 사용함
고유한 값이나 범위 검색이 자주 필요한 경우
자주 조회되는 컬럼에 대해 성능 최적화시
특징
절적한 인덱스가 있을 때만 사용 가능함
대용량 데이터 중에서 극히 일부만 찾을 때 유리함
인덱스를 유지 관리하기 위해 추가적인 리소스가 필요
인덱스 스캔(Index Scan) 종류
인덱스 전체 스캔(Index Full Scan)
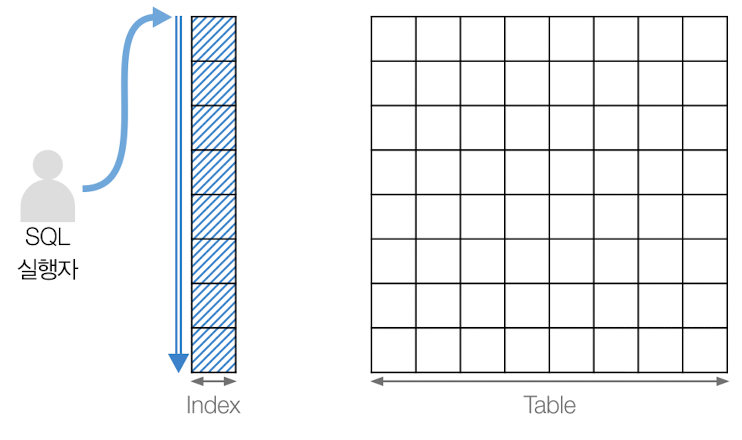
테이블에 접근하지 않고, 인덱스 내의 열만을 참조하여 처음부터 끝까지 스캔하여 데이터에 접근하는 방식
인덱스 크기가 작은 경우 빠른 검색 가능함
테이블의 크기가 큰 경우 전체 테이블 스캔보다 느릴 수 있음
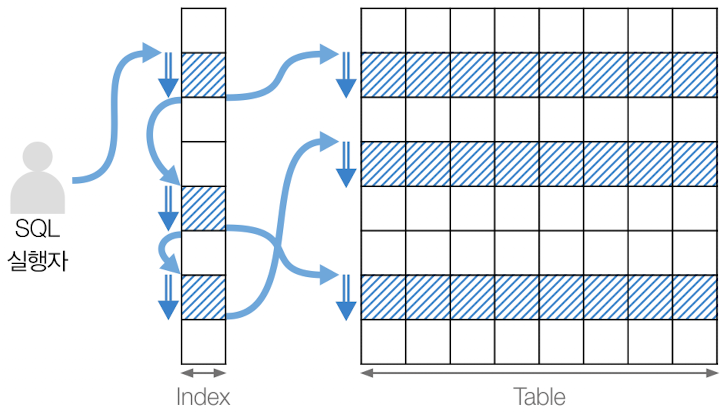
인덱스 범위 스캔(Index Range Scan)
인덱스의 일부 데이터만 읽어오는 방법으로, 인덱스의 범위를 지정하여 빠른 검색 가능
특정 범위 내의 레코드만 읽기 때문에 비용이 적음
검색 범위가 넓을 경우 느릴 수 있음
인덱스 고유 스캔(Index Unique Scan)
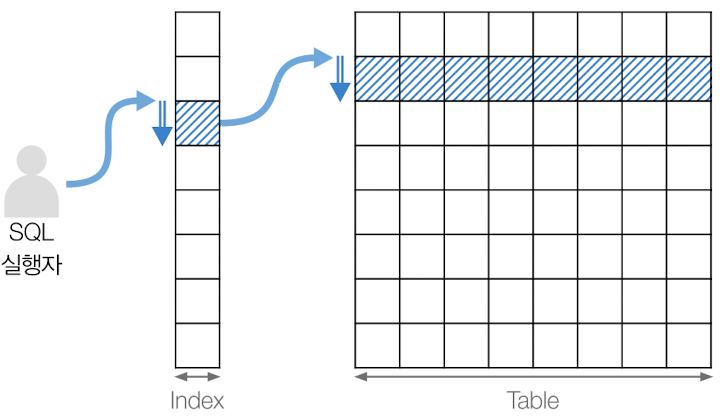
인덱스의 유일한 값을 검색하는 방법으로, 기본키나 고유 인덱스로 테이블에 접근함
하나의 값만 읽기 때문에 비용이 가장 적음(인덱스 스캔 중 가장 효율적인 방식)
인덱스 컬럼이 유일한 값을 가지고 있을 때만 사용 가능
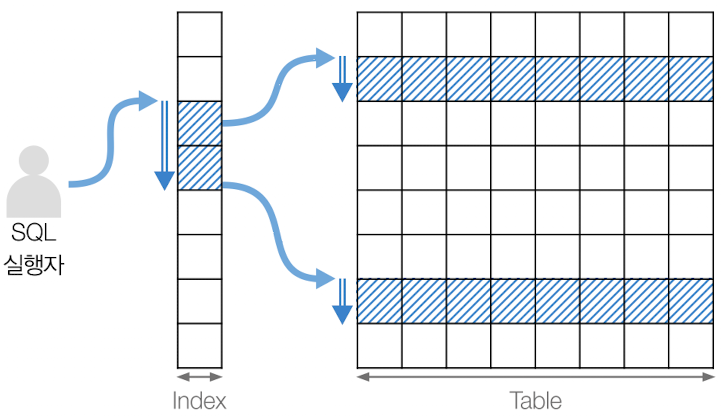
인덱스 루스 스캔(Index Loose Scan)
인덱스에서 필요한 부분만 선택하여 스캔하는 방법으로, 인덱스의 범위를 지정하지 않고 검색을 수행함
인덱스 범위 스캔과 비슷하게 특정 인덱스 범위만 스캔하지만, 중간에 필요없는 인덱스 키 값은 건너뛰고 검색함
인덱스 병합 스캔(Index Merge Scan)
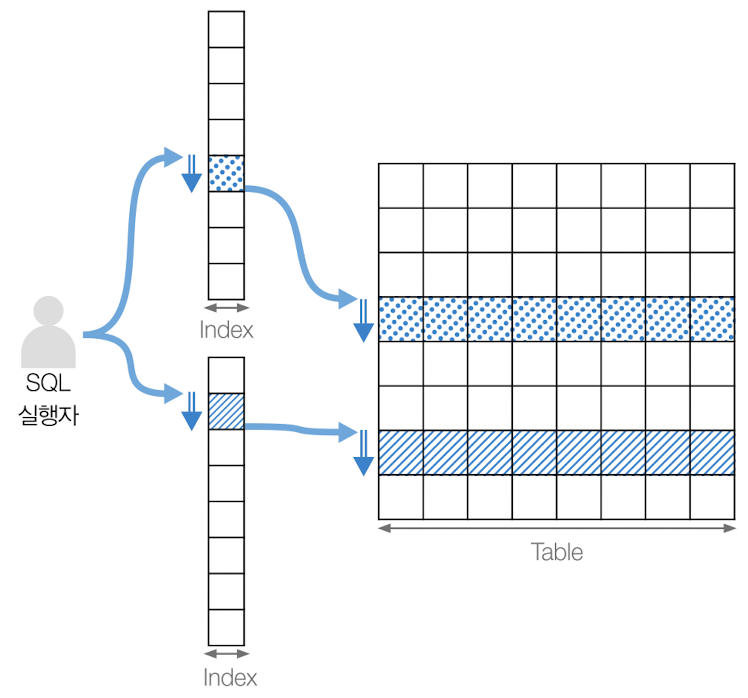
여러 개의 인덱스를 병합하여 검색하는 방법
복잡한 검색 조건을 처리할 수 있음
인덱스의 크기가 작은 경우에만 유용하며, 인덱스 병합에 시간이 걸릴 수 있음
Index를 타지 않는 경우
인덱스를 타는 쿼리임에도 Table Full Scan 방식으로 동작하는 경우가 존재함
인덱스 컬럼의 변형
인덱스에 변형을 가하게 되면, DBMS가 인덱스를 이용하지 않음
인덱스 컬럼의 내부적인 데이터 형 변환
정확한 데이터 타입을 넣어야 인덱스를 탈 수 있음
조건절에 NULL 또는 NOT NULL 사용
부정형 NOT, LIKE, IN, OR 사용
NOT의 경우, 일반적으로 NOT이 아닌 데이터 비율이 많기 때문에 인덱스를 타지 않음
LIKE의 경우, 사용할 때 전체 범위를 설정하면(
%를 앞에도 사용하면) 타지 않음IN의 경우, IN에 포함된 데이터의 비율이 매우 높아서 Table Full Scan을 하는 것이 낫다고 DB에서 판단하면 타지 않음
OR의 경우, DBMS가 최적의 OR 조거을 뽑기 힘들어서 Table Full Scan을 하는 경우가 많음
복합 인덱스의 순서를 정확하게 사용하지 않은 경우
복합 인덱스의 순서가 name 다음 age라면, name -> age 순서로 조건을 걸어야 인덱스를 탈 수 있음
참고
Last updated